ЁЁЁЁжаЧрБЈЁЄжаЧрЭјМЧеп РюШєвЛ МћЯАМЧеп РюдУ
ЁЁЁЁНќЦкЃЌУРЙњзюОпгАЯьСІЕФУНЬхжЎвЛЁЖХІдМЪББЈЁЗдкХІдМФЯЧјЗЈдКЯђOpenAIМАЦфЭЖзЪШЫЮЂШэЙЋЫОЬсЦ№ЧжЗИАцШЈЫпЫЯЃЌжИПиЖўепЮДОаэПЩЪЙгУЦфЪ§АйЭђЦЊЮФеТвдбЕСЗШЫЙЄжЧФмФЃаЭЃЌЖјетаЉСФЬьЛњЦїШЫЯждкгыИУаТЮХЛњЙЙаЮГЩОКељЃЌГЩЮЊПЩППЕФаХЯЂРДдДЁЃ
ЁЁЁЁЫпЫЯЮДУїШЗЬсГіОпЬхЕФОМУвЊЧѓЃЌЕЋГЦБЛИцгІЖдгы"ЗЧЗЈИДжЦКЭЪЙгУЁЖХІдМЪББЈЁЗЖРЬигаМлжЕЕФзїЦЗ"ЯрЙиЕФ"Ъ§ЪЎвкУРдЊЕФЗЈЖЈКЭЪЕМЪЫ№КІ"ИКд№ЃЌЛЙвЊЧѓБЛИцЯњЛйЪЙгУЁЖХІдМЪББЈЁЗАцШЈВФСЯЕФЫљгаAIФЃаЭКЭбЕСЗЪ§ОнЁЃ
ЁЁЁЁдкЭЖЫпжаЁЖХІдМЪББЈЁЗБэЪОдјгкЫФдТгыЮЂШэКЭOpenAIНјааСЫНгДЅЃЌЬсГіСЫЖдЦфжЊЪЖВњШЈЪЙгУЕФЕЃгЧЃЌВЂЬНЬж"гбКУНтОі"ЕФПЩФмадЃЌЕЋЬИХаЮДВњЩњНтОіЗНАИЁЃЕБЕиЪБМф1дТ8ШеЃЌOpenAIЪзДЮеыЖдЁЖХІдМЪББЈЁЗЬсЦ№ЕФЫпЫЯНјааСЫе§ЪНЛигІЃЌГЦЁЖХІдМЪББЈЁЗВЂЮДНВЪіЭъећЕФЙЪЪТЃЌЦфЫпЫЯКСЮоИљОнЁЃОЁЙмШчДЫЃЌЙЋЫОШдШЛЯЃЭћгыЦфНЈСЂНЈЩшадЕФКЯзїЛяАщЙиЯЕЃЌВЂз№жиЦфгЦОУЕФРњЪЗЁЃ
ЁЁЁЁЁЖХІдМЪББЈЁЗЪЧШЋЧђЪзМвЦ№ЫпСНМвЙЋЫОЧжЗИЦфЮФзжзїЦЗАцШЈЕФУРЙњДѓаЭУНЬхЛњЙЙЁЃДЫДЮЫпЫЯРПЊСЫЮДОЪкШЈЪЙгУвбЗЂВМзїЦЗбЕСЗШЫЙЄжЧФмММЪѕЕФ"ЗЈТЩеНвл"аТЦЊеТЃЌЛђНЋГЩЮЊгАЯьAIGC(ЩњГЩЪНШЫЙЄжЧФмЃЉСьгђзпЯђЕФжиДѓЪТМўЁЃ
ЁЁЁЁвЕФкељвщВЛЖЯ АцШЈЫпЫЯЦЕЗЂ
ЁЁЁЁетГЁЫпЫЯв§Ц№СЫвЕФкЙигкФкШнДДзїепгыШЫЙЄжЧФмПЊЗЂепжЎМфШЈвцЦНКтЕФЬжТлЁЃжЇГжепКЭЗДЖдепИїжДвЛДЪЃЌгаШЫШЯЮЊжЊЪЖВњШЈжСЩЯЃЌOpenAIЧжЗИСЫЁЖХІдМЪББЈЁЗЕФРЭЖЏГЩЙћЃЌЩѕжСПЩФмЭўаВЕНаТЮХвЕЕФЖРСЂадЃЛвВгаШЫШЯЮЊЃЌДѓФЃаЭПЩвдЯёШЫвЛбљУтЗббЇЯАЃЌЧжШЈЕФЙиМќдкгкзїЦЗЕФЪфГіФкШнЃЌЖјЗЧЪфШыФкШнЁЃ
ЁЁЁЁУРЙњЪ§зжЙуИцОжЃЈDigital Content NextЃЉЪзЯЏжДааЙйНмЩЁЄН№ЬиЃЈJason KintЃЉдкЩчНЛУНЬхXЃЈдЭЦЬиЃЉЩЯжИГіЁЖХІдМЪББЈЁЗРэгЩГфЗжЃЌЦфжаАќРЈЁЖХІдМЪББЈЁЗЕФФкШнЪЧOpenAIгУРДбЕСЗДѓФЃаЭЕФЙиМќРДдДЃЌвдМАЁЖХІдМЪББЈЁЗЬсЙЉЕФ100ЖрИіGPT-4ЪфГіФкШнКЭЁЖХІдМЪББЈЁЗБЈЕРЮФеТИпЖШЯрЫЦЕФР§згЁЃ
ЁЁЁЁУРЙњзїМвЁЂПЦММЦРТлМвЕЄФсЖћЁЄНмИЅРяЫЙЃЈDaniel JeffriesЃЉдђЬсГіЯрЗДЙлЕуЃЌШЯЮЊвЊЧѓУПИіШЫЮЊбЕСЗЪ§ОнжЇИЖЪкШЈЗбЪЧВЛЧаЪЕМЪЕФЃЌетвВВЛЪЧУРЙњАцШЈЗЈЫљЬИТлЕФЙиМќЃЌ"АцШЈЗЈЕФзкжМЪЧЗРжЙШЫУЧЭъШЋИДжЦЛђНќЫЦИДжЦФкШнЃЌВЂЮЊСЫЩЬвЕРћвцНЋЦфЗЂВМЁЃ"
ЁЁЁЁЫћЛЙЩљГЦЃЌGPTОЋШЗИДжЦЁЖХІдМЪББЈЁЗФкШнЪЧШЫЮЊВйзнЕФНсЙћЁЃ"УЛгаШЫФмгУЫћУЧЫљЮНЕФЬсЪОжиЯжФЧИіж№зжЕФЪфГіЁЁПЩФмЪЧГЬађдБЭЈЙ§APIЬивтжИСюЫќбАевФГЦЊЬиЖЈЕФЮФеТЃЌВЂШУЫќЪфГіЮФеТЕФвЛВПЗжЁЁШчЙћЮвШУЫќШЅеввЛЦЊЁЖХІдМЪББЈЁЗЕФЮФеТВЂЪфГіЃЌФЧУДд№ШЮдкЮвЃЌЖјВЛЪЧетИіФЃаЭЁЃПіЧветИіЙІФмЭъШЋВЛашвЊЛњЦїбЇЯАММЪѕЃЌЪЎМИФъЧАЕФБрГЬПтОЭФмзіЕНЁЃ"
ЁЁЁЁЖдгкЯЏОэЖјРДЕФAIДѓФЃаЭРЫГБЃЌВЛЭЌЕФФкШнДДзїепКЭУНЬхЛњЙЙвВгазХНиШЛВЛЭЌЕФЬЌЖШЁЃ
ЁЁЁЁВПЗжаТЮХЛњЙЙбЁдёгыПЦММЦѓвЕКЯзїЁЃШЅФъ7дТЃЌУРСЊЩчгыOpenAIДяГЩавщЃЌЪкШЈOpenAIЪЙгУУРСЊЩчВПЗжаТЮХДцЕЕЃЌвдЬНЫїЩњГЩЪНAIдкаТЮХСьгђЕФгІгУЁЃ12дТЃЌЕТЙњДѓаЭУНЬхЙЋЫОАЂПЫШћЖћЁЄЪЉЦеСжИёЃЈAxel SpringerЃЉгыOpenAIНЈСЂШЋЧђКЯзїЛяАщЙиЯЕЃЌИљОнавщЃЌChatGPTгУЛЇгаШЈЯодФЖСИУГіАцЩчЦьЯТУНЬхЫљДДзїЕФОЋбЁФкШнЃЌЭЌЪБЦфФкШнНЋБЛгУгкЭЦНјДѓгябдФЃаЭЕФбЕСЗЁЃЁЖЛЊЖћНжШеБЈЁЗаТЮХМЏЭХдђе§дкПМТЧЯђAIПЊЗЂШЫдБЪеШЁЪЙгУЦфжаФкШнЕФЗбгУЃЌНЋЩњГЩЪНAIЪгЮЊЮДРДвЕМЈЕФжЇГжЁЃ
ЁЁЁЁЕБЕиЪБМф1дТ4ШеЃЌOpenAIЕФжЊЪЖВњШЈКЭФкШнЪзЯЏЬРФЗЁЄТГБіЃЈTom RubinЃЉдкНгЪмВЩЗУЪББэЪОЃЌЙЋЫОНќЦкгыЪ§ЪЎМвГіАцЩЬеЙПЊСЫгаЙиаэПЩавщЕФЬИХаЃЌ"ЮвУЧе§ДІгкЖрГЁЬИХажаЃЌе§дкгыЖрМвГіАцЩЬНјааЬжТлЁЃЫћУЧЪЎЗжЛюдОЛ§МЋЃЌетаЉЬИХаНјеЙСМКУЁЃ"
ЁЁЁЁгыДЫЯрЖдгІЃЌЖрМвУНЬхдкЦфЭјеОЩЯзшжЙOpenAIЩЈУшЦНЬЈФкШнЁЃИљОнЁЖЮРБЈЁЗБЈЕРЃЌздЁЖХІдМЪББЈЁЗКѓЃЌCNNЁЂТЗЭИЩчЁЂЁЖжЅМгИчТлЬГБЈЁЗЃЈThe Chicago TribuneЃЉЁЂЁЖПАХрРЪББЈЁЗЃЈThe Canberra TimesЃЉЁЂЁЖХІПЈЫЙЖћЯШЧ§БЈЁЗЃЈThe Newcastle HeraldЃЉЕШУНЬхЗзЗзаћВМзшжЙИУааЮЊЁЃЦфжаЃЌЗЈЙњЙуВЅЕчЬЈЃЈRadio FranceЃЉБэЪОЃЌзшжЙOpenAIЛњЦїШЫЪЧЮЊСЫБмУт"ФкШнЮДОЪкШЈОЭБЛТгЖсЁЃ"
ЁЁЁЁЪТЪЕЩЯЃЌЩњГЩЪНAIУцСйзХДѓСПЧжЗИАцШЈЕФжИПиЁЃ
ЁЁЁЁ2023Фъ7дТ10ШеЃЌУРЙњЯВОчбндБКЭзїМвШјРЁЄЯЃЖћИЅТќЃЈSarah SilvermanЃЉвдМАСэЭтСНУћзїМвЦ№ЫпMetaКЭOpenAIЃЌжИПиЦфЧжЗИАцШЈЁЃ9дТ19ШеЃЌУРЙњзїМваЛсвдМААќРЈЁЖШЈСІЕФгЮЯЗЁЗджјзїепЧЧжЮЁЄRЁЄRЁЄТэЖЁЃЈGeorge R.R. MartinЃЉдкФкЕФ17ЮЛУРЙњжјУћзїМвЖдOpenAIЗЂЦ№МЏЬхЫпЫЯЃЌГЦOpenAIдкЮДОЪкШЈЕФЧщПіЯТЪЙгУдИцзїМвЕФАцШЈзїЦЗбЕСЗЦфДѓгябдФЃаЭЁЃ12дТЃЌЖрУћЦеРћВпНБЕУжїЦ№ЫпOpenAIКЭЮЂШэРФгУздМКзїЦЗбЕСЗДѓФЃаЭЃЌжИГіетбљЕФааЮЊЮовЩЪЧдк"ЙЮШЁ"зїМвУЧЕФзїЦЗКЭЦфЫћЪмАцШЈБЃЛЄЕФВФСЯЁЃЫћУЧЯЃЭћЛёЕУОМУХтГЅЃЌВЂвЊЧѓетаЉЙЋЫОЭЃжЙЧжЗИзїМвУЧЕФАцШЈЁЃ
ЁЁЁЁОнВЛЭъШЋЭГМЦЃЌзд2022Фъ11дТжС2023Фъ10дТЃЌНіУРЙњМгжнББЧјЗЈдКБувбОЪмРэСЫ10Ц№ЃЌАцШЈШЫЦ№ЫпStabilityAIЁЂOpenAIЁЂMetaЁЂAlphabetЕШAIGCбаЗЂЦѓвЕЮДОЪкШЈЃЌРћгУАцШЈзїЦЗНјааФЃаЭбЕСЗЕФАИМўЁЃ
ЁЁЁЁДЋЭГЗЈТЩПђМмЯТЕФФбЬт
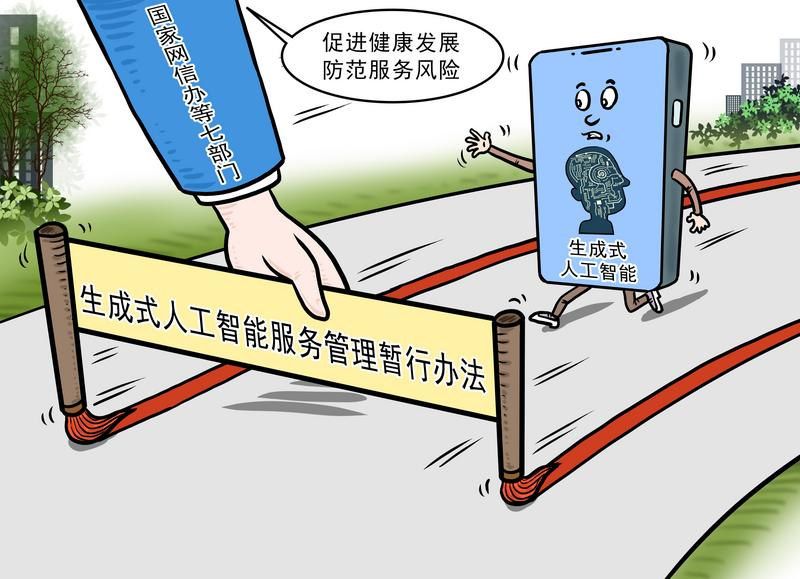
ЁЁЁЁетГЁгЩЁЖХІдМЪББЈЁЗЖдOpenAIЕФЫпЫЯв§ЗЂЕФжЊЪЖВњШЈжЎељЃЌВЛНіНідкУРЙњв§Ц№СЫМЄСвЕФЬжТлЃЌИќЪЧНвЪОСЫШЋЧђЗЖЮЇФкAIгыФкШнДДзїепжЎМфШЈвцБпНчЕФЦеБщадЮЪЬтЁЃдкЮвЙњЃЌЗЈТЩВуУцЩаЮДЖдЩњГЩЪНAIЖдАцШЈзїЦЗЕФЪЙгУзїГіУїШЗЙцЖЈЃЌДѓФЃаЭдкжЊЪЖВњШЈЕФЪЙгУКЭБЃЛЄЗНУцв§ЗЂЕФЬжТлвВгњбнгњСвЁЃ
ЁЁЁЁзїЮЊздШЛгябдДІРэЯЕЭГЃЌДѓаЭгябдФЃаЭЃЈLLMЃЉЭЈЙ§ДѓСПЮФБОгяСЯПтНјаабЕСЗЃЌШЛКѓИљОнЫќЫљбЇЕНЕФФкШнРДЛиД№ЮЪЬтЛђЩњГЩЮФБОЃЌЦфбЇЯАЕФФмСІКмДѓГЬЖШЩЯвРРЕгкКЃСПЪ§ОнЁЃЕБЯТЙигкЩњГЩЪНAIСьгђЕФАцШЈОРЗзЃЌгааэЖргаЙиЪЙгУЮДОЪкШЈЕФАцШЈзїЦЗНјааДѓФЃаЭбЕСЗЕФааЮЊЃЌЧвгаМЃЯѓЯдЪОДЋЭГЕФАцШЈФЃЪНдкДѓФЃаЭЪБДњПЩФмЛсЪЇСщЁЃ
ЁЁЁЁ"АДееЮвЙњЗЈТЩРДХаЖЯЃЌДѓФЃаЭдкбЕСЗНзЖЮЖдгкЪ§ОнЕФЪЙгУЪЧЗёЪєгкАцШЈЧжШЈЃЌвРОЩДцдкељвщЃЌКмФбИјГіШЗЖЈадЕФНсТлЁЃ"жаЙњеўЗЈДѓбЇжЊЪЖВњШЈбаОПжааФЬидМбаОПдБЁЂББОЉМЮЮЋТЩЪІЪТЮёЫљТЩЪІедеМСьжИГіЃЌвЛАуЖјбдДѓФЃаЭбЕСЗНзЖЮАќКЌШ§жжааЮЊЃКЛёШЁЁЂДцДЂЁЂДІРэЁЃ"ЛёШЁааЮЊРрЫЦгкЯпЩЯфЏРРЭјвГКЭЯпЯТдФЖСЪщМЎЃЌШчЙћжЛЪЧНгДЅВЛДцдкКѓајЕФДЋВЅРћгУЃЌЪЧВЛЙЙГЩЧжШЈЕФЁЃ"ЭЌЪБЫћЧПЕїЃЌдкЛёШЁНзЖЮашвЊЙизЂЛёШЁКЯЗЈадЮЪЬтЃЌ"БШШчЖдЗНЪЕЪЉММЪѕБЃЛЄДыЪЉЃЌЕЋФуЭЈЙ§ЙцБметаЉДыЪЉШЅзЅШЁЗўЮёЦїРяЕФФкШнЃЌЪЧПЩФмЙЙГЩЧжШЈЕФЁЃ"
ЁЁЁЁедеМСьжИГіЃЌАДеежјзїШЈЗЈЃЌДѓФЃаЭбЕСЗЕФДцДЂНзЖЮжївЊЛсЩцМАЪЧЗёЧжЗИШЈРћШЫЕФИДжЦШЈЁЃ"ЕЋДѓФЃаЭбЕСЗВЛЪЧЙЋПЊЕФЭтВПЪЙгУЃЌДгДЋЭГЕФНЧЖШРДНВВЛКУЗЂЯжЃЌвВКмФбХаЖЈЕНЕздьГЩСЫЪВУДЫ№ЪЇЃЌЙњФквВУЛгаУїШЗЕФСЂЗЈКЭЯрЙиЕФЫОЗЈХаР§ЃЌКмФбИјГіУїШЗЕФНсТлЁЃвђЮЊЧжЗИИДжЦШЈвЛАуЖМЪЧИДжЦЭЌЪБНјааДЋВЅКЭРћгУЁЃ"
ЁЁЁЁЖдгкДІРэНзЖЮЃЌЬкбЖбаОПдКИпМЖбаОПдБжьПЊіЮдјБэЪОЃЌФЃаЭФкВПЕФФкШнЗжЮіДІРэааЮЊЖдгІАцШЈЗЈЩЯЕФКЮжжШЈРћДцдквЩЮЪЃЌЧвРэТлНчКЭЪЕЮёНчФПЧАЩаЮДгаУїШЗНсТлЁЃ
ЁЁЁЁжьПЊіЮжИГіЃЌгаЙлЕуШЯЮЊ"зїЦЗДІРэ"ааЮЊТфШыАцШЈЗЈжа"ИФБрШЈ"ЕФЙцжЦЗЖГыЃЌЕЋЫљЮНЕФИФБрШЈЪЧжИИФБрМШгазїЦЗаЮГЩаТзїЦЗЕФааЮЊЃЌШчЙћЪЧЖдзїЦЗЪ§ОнНјааЗжЮіДІРэЃЌВЂЩњГЩАќКЌвЛЖЈФЃЪНЁЂЧїЪЦвдМАЯрЙиадЕФВЮЪ§ЃЌетвЛЙ§ГЬВЛЩцМАаТзїЦЗЕФаЮГЩЃЌУїЯдФбвдЦѕКЯ"ИФБрШЈ"ЕФвЊЧѓЁЃЛЙгаЙлЕуШЯЮЊЃЌЩЯЪіааЮЊВЛЪєгкАцШЈЙцжЦЕФШЈРћЗЖГыЁЃАцШЈЗЈзёб"ЫМЯыБэДяЖўЗжЗЈ"ЕФЛљБОТпМЃЌЧПЕї"ВЛБЃЛЄздШЛШЫЕФЫМЯыЃЌжЛБЃЛЄздШЛШЫЖдгкЫМЯыЕФЭтдкБэДя"ЁЃGPTФЃаЭЭЈЙ§ВЛЖЯбЇЯАКЃСПзїЦЗжаВЛЭЌЮФзжжЎМфХХСазщКЯЕФИХТЪКЭЙцТЩЃЌШЛКѓФкЛЏЮЊздЩэЕФФЃаЭВЮЪ§ЃЌЖдгкзїЦЗНіНіЪЧНјааЭГМЦбЇвтвхЩЯЮФзжзщКЯИХТЪЕФбЇЯАЃЌВЛЪЧЮЊСЫЪЙгУКЭеЙЪОзїЦЗжаЕФБэДяадФкШнЃЌвђДЫврВЛЪєгкАцШЈЗЈвтвхЩЯЕФзїЦЗРћгУааЮЊЁЃ
ЁЁЁЁ"ФПЧАЮвЙњдкЗЈТЩВуУцЩЯУЛгаЖдЩњГЩЪНAIЪЙгУАцШЈзїЦЗЕШЗНУцгаОпЬхЙцЖЈЃЌЕЋДцдкВПУХЙцеТВуУцЕФЙцЖЈЁЃ"ББОЉДѓГЩТЩЪІЪТЮёЫљжЊЪЖВњШЈгыПЦММДДаТзщСЊКЯИКд№ШЫаЄьЊжИГіЃЌЮвЙњЖдЩњГЩЪНAIЪЙгУзїЦЗЕФЙцЗЖжївЊМЏжадкЁЖЩњГЩЪНШЫЙЄжЧФмЗўЮёЙмРэднааАьЗЈЁЗЃЌЦфжаЕкЦпЬѕЙцЖЈЃЌЩњГЩЪНШЫЙЄжЧФмЗўЮёЬсЙЉепгІЕБвРЗЈПЊеЙдЄбЕСЗЁЂгХЛЏбЕСЗЕШбЕСЗЪ§ОнДІРэЛюЖЏЃЛЩцМАжЊЪЖВњШЈЕФЃЌВЛЕУЧжКІЫћШЫвРЗЈЯэгаЕФжЊЪЖВњШЈЁЃЦфЬиЕудкгкЖдAIбЕСЗЪЙгУАцШЈзїЦЗНЯЮЊПЊЗХЃЌжЛвЊВЛЧжКІАцШЈзїЦЗИДжЦШЈЁЂаХЯЂЭјТчДЋВЅШЈЕШжјзїШЈЗЈЩЯЙцЖЈЕФШЈРћМДПЩЁЃ
ЁЁЁЁжЕЕУвЛЬсЕФЪЧЃЌЮвЙњжјзїШЈЗЈЕк24ЬѕЙцЖЈСЫ"КЯРэЪЙгУЬѕПю"ЃЌдкЬиЖЈЕФЬѕМўЯТЃЌЗЈТЩдЪаэЫћШЫздгЩЪЙгУгажјзїШЈЕФзїЦЗЃЌЖјВЛБиеїЕУШЈРћШЫаэПЩЃЌВЛЯђЦфжЇИЖБЈГъЕФКЯЗЈааЮЊЁЃЖјХаЖЈЪЧЗёЪєгк"ЬиЖЈЕФЬѕМў"ЃЌЦфжавЛИіживЊБъзМЪЧЪЧЗёгУгкгЏРћФПЕФЁЃ
ЁЁЁЁДѓФЃаЭбЕСЗЪЧЗёФмЪЪгУ"ЬиЖЈЕФЬѕМў"ЃЌБЛЙщШы"КЯРэЪЙгУЗЖГы"ЃПаЄьЊШЯЮЊЃЌЩњГЩЪНAIзЅШЁФкШнЯдШЛЪєгкЩЬвЕгЏРћФПЕФЃЌЙЪЮоЗЈЙЙГЩКЯРэЪЙгУЁЃКЯРэЪЙгУжЦЖШжЎЫљвдЯожЦжјзїШЈЃЌЪЧвђЮЊжјзїШЈБОЩэМДЪЧЗЈТЩИГгшзїепЬиЪтЕФТЂЖЯШЈРћЃЌЕЋВЛФмвђЦфЖјзшАШЫУЧбЇЯАгыЩчЛсЗЂеЙЁЃИљОнФПЧАЗЈТЩРДПДЃЌЩњГЩЪНAIзЅШЁЫфВЛЙЙГЩКЯРэЪЙгУЃЌЕЋдкЮДРДЫцзХЦфживЊадж№НЅХЪЩ§ЃЌЯргІЗЈЙцПЩФмЛсгаЫљБфЛЏЁЃ
ЁЁЁЁаЄьЊЙлВьЕНЙњФкФПЧАЫфШЛЛЙЮДБЌЗЂДѓаЭУЌЖмЃЌЕЋВЛФбПДГідкаЁЕФФкШнДДзїепгыAIЗўЮёЬсЙЉепжЎМфвбДцдкВЛЩйФІВСЁЃ"ЩњГЩЪНAIБОЩэдЫааЛњжЦНЯЮЊИДдгЃЌЯывЊжЄУїЦфЧжШЈШЗЪЕДцдкКмДѓЕФРЇФбЃЌетШЗЪЕдквЛЖЈГЬЖШЩЯМгДѓСЫБЛЧжШЈепЕФЮЌШЈГЩБОЁЃ"Ы§ШЯЮЊЃЌФПЧАФкШнЩњВњЗНЫљвРРЕЕФЗЈТЩБЃЛЄвРОЩЪЧжјзїШЈЗЈЃЌШЛЖјжјзїШЈЗЈЛЙднЮДЫцAIЗЂеЙЖјИќаТЃЌвђДЫФкШнЩњВњЗНШєЯыБЃЛЄздМКЕФзїЦЗВЛБЛAIЪЙгУЃЌзюКУЕФАьЗЈЛЙЪЧвРОнжјзїШЈЗЈЕкЫФЪЎОХЬѕЃЌЖдЦфЗЂВМдкЙЋЙВЦНЬЈЕФзїЦЗВЩШЁвЛЖЈЕФММЪѕЪжЖЮНјааБЃЛЄЃЌЭЌЪБдкЯрЙиЮФБОжаУїШЗБэЪОЦфФкШнВЛЕУБЛгУгкAIбЕСЗЁЃ
ЁЁЁЁбАевАцШЈКЭММЪѕЕФаТЦНКт
ЁЁЁЁAIДѓФЃаЭЪБДњПЊЦєЃЌгІШчКЮПДД§ФкШнАцШЈБЃЛЄКЭШЫЙЄжЧФмММЪѕжЎМфЕФЙиЯЕЃП
ЁЁЁЁдкаЄьЊПДРДЃЌФПЧААцШЈгыЩњГЩЪНAIЗЂеЙЪЧЯрЛЅжЦдМЕФЁЃ"АцШЈжЦЖШЪЕМЪЩЯОЭЪЧЭЈЙ§ИГгшзїепЬиЪтТЂЖЯЕиЮЛЃЌвдЮЌЛЄгыЙФРјЦфжЧЛлДДдьЁЃЮЊДйНјЩњГЩЪНAIЗЂеЙЃЌАцШЈжЦЖШПЩФмашвЊЪЪЕБШУВНЃЌдкДѓЪ§ОнЪБДњжабАеввЛИіаТЕФЦНКтЁЃЖјДгЗЈТЩВуУцЩЯРДПДЃЌЦНКтЕФЗНЪНПЩФмЪЧГіЬЈЯрЙиСьгђЕФзЈУХСЂЗЈЃЌДгЖјШЗСЂЖРЬиЕФБъзМЁЃ"
ЁЁЁЁжаЙњПЦбЇдКащФтОМУгыЪ§ОнПЦбЇбаОПжааФбаОПзщГЩдБЁЂжаПЦЪ§зжДѓФдбаОПдКдКГЄСѕЗцШЯЮЊЃЌжјзїШЈжЦЖШЕФИљБОМлжЕдкгкЮЌЛЄИіШЫРћвцгыЙЋЙВРћвцжЎМфЕФЦНКтЁЃЫцзХЩњГЩЪНAIЕШММЪѕЕФЗЂеЙЃЌЪ§ОнвЊЫивбГЩЮЊзюОпЪБДњЬиеїЕФЩњВњвЊЫиЃЌЪ§ОнЖдЬсИпШЫЙЄжЧФмКЭЪ§зжЛЏММЪѕФмСІЕФзїгУе§ВЛЖЯЭЙЯдЁЃЕЋШЫЙЄжЧФмЗЂеЙБГКѓЃЌЪ§ОнЕФРћгУКЭЗжХфЩцМАЕНЖрЗНУцИДдгЮЪЬтЃЌашвЊзлКЯПМТЧММЪѕЁЂЗЈТЩЁЂТзРэЕШЖрИіЮЌЖШРДевЕНКЯРэЪЙгУЕФЦНКтЕуЁЃзмЬхРДЫЕЃЌЩњГЩЪНAIФЃаЭгыжЊЪЖВњШЈжЎМфГЪЯжГівЛжжВЉоФЕФЙ§ГЬЁЃ
ЁЁЁЁББОЉЪІЗЖДѓбЇаТЮХДЋВЅбЇдКбЇЪѕЮЏдБЛсжїШЮЁЂНЬЪкЃЌББОЉЪІЗЖДѓбЇДЋВЅДДаТгыЮДРДУНЬхЪЕбщЦНЬЈжїШЮгїЙњУїНјвЛВННтЪЭЕРЃЌЩњГЩЪНAIЕФММЪѕдРэЪЧНсКЯДѓСПгяСЯЪ§ОнЃЌЙЙНЈДѓгябдФЃаЭЃЈLLMЃЉЃЌвдChatGPTЮЊР§ЃЌЭЈЙ§етжжЗНЪНПЩЪЙЦфОпБИИпгкШЫРрЦНОљЫЎзМЕФЛЅЖЏСФЬьФмСІЃЌетаЉгяСЯЪ§ОнвдЧЇвкМЖЮЊЕЅЮЛЃЌЕБЧАДгЪТЩњГЩЪНAIЕФДДвЕЙЋЫОЯдШЛВЛОпБИЭъШЋжЇИЖгяСЯЪ§ОнЕФФмСІЃЌвђДЫКмШнвзВњЩњжЊЪЖВњШЈОРЗзЁЃ
ЁЁЁЁЮЊДЫЃЌЫћдкМИФъЧАБуЬсГіСЫЮЂАцШЈЕФИХФюЁЃЮЂАцШЈЪЧжИЃЌдкММЪѕЗЂеЙЙ§ГЬжаКтСПгяСЯЪ§ОнЕФМлжЕЁЃБШШчЃЌЖдгкбЇЪѕТлЮФЖјбдЃЌВЛЭЌТлЮФЕФЪ§ОнЃЈЯТдиСПЁЂв§гУСПЕШЃЉВЛЭЌЃЌгІЕБОпБИВЛЭЌЕФМлжЕЃЌЖјЗЧВЩгУЭГвЛЁЂОВЬЌЕФМлжЕШЈжиНјааКтСПЁЃ"АцШЈМлжЕВЂЗЧКуЖЈВЛБфЃЌгІЕБИљОнАцШЈжїЬхЩњЬЌЮЛЕФЬЌЪЦЙЙНЈЖЏЬЌИЁЖЏЕФМлжЕШЈжи"ЁЃ
ЁЁЁЁгїЙњУїжИГіЃЌЮЂАцШЈНЋНсКЯгяСЯМлжЕЃЌЖдАцШЈМлжЕНјааЯИЗжЃЌЦНКтСЫАцШЈЫљгаЗНКЭАцШЈЪЙгУЗНжЎМфЕФЙиЯЕЃЌИГгшАцШЈзЪдДИќДѓЕФздгЩЖШКЭСщЛюадЁЃИќживЊЕФЪЧЃЌФмМѕЧсЩњГЩЪНAIЙЋЫОЕФжЇИЖГЩБОгыЧжШЈЗчЯеЁЃ
ЁЁЁЁеыЖдДЫРрЮЪЬтЃЌББОЉЪІЗЖДѓбЇаТЮХДЋВЅбЇдКЁЂМЦЫуДЋВЅбЇбаОПжааФИБНЬЪкЃЌКМжнЪаБѕНЧјеуЙЄДѓЭјТчПеМфАВШЋДДаТбаОПдКЬиЦИбаОПдБуЩгТШЯЮЊЃЌЁЖХІдМЪББЈЁЗЦ№ЫпOpenAIЕФАИМўвЛЖЈГЬЖШЩЯЛНабСЫЙњФкAIЦѓвЕЙигкДѓФЃаЭбЕСЗЪ§ОнЕФАцШЈвтЪЖЁЃЩњГЩЪНAIЕФММЪѕЗЂеЙЪЧвЛИіВЛЖЯздЮвНјЛЏЕФЙ§ГЬЃЌЫцзХММЪѕЕФЗЂеЙЃЌAIGCбаЗЂжїЬхAIгыАцШЈЗНзюжегІевЕНвЛжжЛЅЛнЛЅРћЕФКЯзїЗНЪНЁЃ
ЁЁЁЁгыДЫЭЌЪБЃЌЖрЮЛвЕФкШЫЪПЖдМЧепБэЪОЃЌШЗСЂАцШЈБЃЛЄддђЪЧАцШЈЩњЬЌГжајЁЂгаађЁЂЖЏЬЌЁЂЦНКтЗЂеЙЕФЧАЬсЁЃМгЧПжЊЪЖВњШЈБЃЛЄПЩвдЬсЩ§ЦѓвЕДДаТФмСІКЭЦѓвЕбаЗЂЭЖШыЃЌвВЖдАцШЈЩњЬЌЯТЕФДДзїепЁЂПЦбаШЫдБЕШжюЖрДІгкВЛЭЌСьгђЕФДгвЕШЫдБОпгаМЄРјДДаТКЭЬсЩ§ЛюСІЕФзїгУЁЃ
ЁЁЁЁЪТЪЕЩЯЃЌМрЙмгыЗЂеЙЃЌВЂВЛЪЧвЛИіЖўдЊЖдСЂЕФбЁдёЁЃдкКмГЄвЛЖЮЪБМфФкЃЌЮвЙњдкжЊЪЖАцШЈКЭAIММЪѕЕФЙиЯЕЮЪЬтЩЯЃЌвВГЪЯжГівЛжжУўзХЪЏЭЗЙ§КгЕФзДЬЌЁЃуЩгТНЈвщЃЌЮЊБмУтАцШЈЗНгыAIGCбаЗЂжїЬхжЎМфЕФжЊЪЖВњШЈФІВСЃЌЮвЙњеўИЎгІНјвЛВНЙизЂПЊдДЪ§ОнМЏЕФПЊЗЂЃЌЙФРјЪмВЦеўжЇГжЕФПЦбаЕЅЮЛЁЂЮФЛЏЕЅЮЛПЊЗХбЕСЗЪ§ОнЃЌМгЧПгыЩчЛсСІСПЕФаЭЌЁЃ
ЁЁЁЁдкШЮКЮвЛИіСьгђЃЌМрЖНЖМЪЧгаБивЊЕФЃЌдкШЫЙЄжЧФметИіСьгђвВЪЧШчДЫЁЃВЛЙ§ЃЌеыЖдДІгкЦ№ВННзЖЮЕФаТаЫММЪѕВњвЕЃЌуЩгТБэЪОЃЌЗЈТЩМрЙмгІЕБдкЛ§МЋЙФРјЗЂеЙДДаТЕФЛљДЁЩЯЃЌЛЎЖЈЗЂеЙКьЯпЃЌОЁПЩФмЮЊЩњГЩЪНAIЬсЙЉЯрЖдПЊЗХЕФЗЂеЙПеМфЁЃ"АцШЈБЃЛЄВЂВЛЪЧЯожЦВњвЕЗЂеЙЃЌЖјЪЧв§ЕМКЭБЃеЯЯрЙиВњвЕЕФСМадЗЂеЙ"ЁЃ
жаЙњ
ЧрФъБЈ
жаЧр
ПДЕу
жаЧр
аЃдА
ЧрДД
ЭЗЬѕ
ОЉICPБИ13016345КХ-8 |  ОЉЙЋЭјАВБИ 11010102004843КХ|24аЁЪБЮЅЗЈКЭВЛСМаХЯЂОйБЈЕчЛАЃК010-64098588
ОЉЙЋЭјАВБИ 11010102004843КХ|24аЁЪБЮЅЗЈКЭВЛСМаХЯЂОйБЈЕчЛАЃК010-64098588
ЛЅСЊЭјаТЮХаХЯЂЗўЮёаэПЩжЄ10120170007КХ |діжЕЕчаХвЕЮёОгЊаэПЩжЄA2.B1-20232628/ОЉB2-20224905КХ|аХЯЂЭјТчДЋВЅЪгЬ§НкФПаэПЩжЄ0105108КХ
ЙВЧрЭХжабыжїАь жаЙњЧрФъБЈжїЙм жаЧрЭјаТУНЬхПЦММЃЈББОЉЃЉгаЯоЙЋЫОАцШЈЫљга















